Node DIY part 1 - Distributed tracing
- 16 minsIntro
This is a first post of the series called Node DIY - a guide that will explain how seemingly complex tools/frameworks/ideas work under the hood and what is at the core of them. I will try to introduce the topic and implement a bare-bones, no dependencies solution. It will be far from production ready, but that’s the point.
Today’s topic is distributed tracing. Distributed tracing is a process of identifying the path that a request (or other forms of activity, but in this article I’ll focus on HTTP) takes traveling through every part of your system.
When I first tried out newrelic I was curious how they were able to trace all of the interactions between my services and all it took was one function call in the application entry point.
Communication
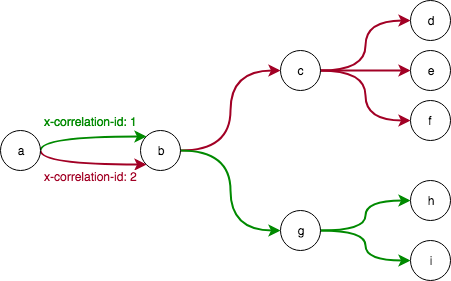
I knew that the tracing information must be kept somewhere in the HTTP request. There is no side channel, because the library works across closed environments (different machines, vms, containers). So I’ve setup a small two app example with newrelic running on it. Made a request from one service to another and checked out the output.

And there it is: x-newrelic-id and x-newrelic-transaction. Ok, that means that we need some way to propagate those headers and make sure we do not mix them up.
Test servers
To test the results of your library, we setup two servers talking to each other. The server 1 forwards first request to server 2 with a 3 second delay and the second request without the delay. Server 2 just responds with status 200 and 'Hello, World!'. If everything goes right, we should observe log entries like this:
- Incoming request 1 with header 1
- Incoming request 2 with header 2
- Response for request 2 with header 2
- Response for request 1 with header 1
Full code below:
Server 1:
require('./load-tracing');
const http = require('http');
const hostname = '127.0.0.1';
const port = 3000;
const port2 = 3001;
let delay = 3;
const server = http.createServer((req, res) => {
console.log('s1: curl headers', req.headers);
setTimeout(() => {
http.request({host: hostname, port: port2}, (response) => {
console.log('s1: response', response.headers);
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello, World!');
}).end();
}, delay * 1000);
delay = 0;
});
server.listen(port, hostname, () => {
console.log(`Server running at https://${hostname}:${port}/`);
});
Server 2:
require('./load-tracing');
const http = require('http');
const hostname = '127.0.0.1';
const port2 = 3001;
const server2 = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello, World!');
});
server2.listen(port2, hostname, () => {
console.log(`Server running at https://${hostname}:${port2}/`);
});
Part 1 - Shimming
Node.js has a method that is called every time there is an event associated with a server (for example a request comes in) and there is another method that is called when we create an outgoing connection. They are http.Server.emit and http.request respectively. Our goal is to change them so that we can add our own custom headers there.
JavaScript being a language that is easily extensible, allows replacing built-in functions by simply assigning a new function to them. This is quite awesome but you have to be extremely careful not to screw things up.
The act of making such modifications is called shimming. Ok so let’s try and implement a basic shimmer:
function wrap(nodule, name, wrapper) {
const original = nodule[name];
const wrapped = wrapper(original);
nodule[name] = wrapped;
}
Just 3 lines, we get the original function, wrap it in a wrapper, and replace it. That simple. There is one requirement for the wrapper function, it has to be a function that takes the original function as an argument and returns a function which takes the arguments of the original function.
Part 2 - unique identifiers
We need some way to distinguish between requests - this is a short implementation of uuid v4 taken from stackoverflow and modified to be easier to read:
const crypto = require('crypto');
const pattern = `${1e7}-${1e3}-${4e3}-${8e3}-${1e11}`;
function uuidv4() {
return pattern.replace(
/[018]/g,
c => (c ^ crypto.randomBytes(1)[0] & 15 >> c / 4).toString(16)
);
}
Nothing fancy, just random bits.
Part 3 - naive approach
So far we know how to inject our custom headers with some unique identifier, but how do we know keep track of the headers when we have multiple requests coming through?
A naive implementation might look something like this:
let uuid;
wrap(http.Server.prototype, 'emit', function (original) {
return function (event, incomingMessage, serverResponse) {
let returned;
if (event === 'request') {
if (incomingMessage.headers[PROPAGATE_HEADER_NAME]) {
uuid = incomingMessage.headers[PROPAGATE_HEADER_NAME];
} else {
uuid = uuidv4();
}
serverResponse.setHeader(PROPAGATE_HEADER_NAME, uuid);
returned = original.apply(this, arguments);
} else {
returned = original.apply(this, arguments);
}
return returned;
};
});
wrap(http, 'request', function (original) {
return function (options) {
options.headers = options.headers || {};
options.headers[PROPAGATE_HEADER_NAME] = uuid;
return original.apply(this, arguments);
};
});
When we run this code in our test servers it outputs:
s1: curl headers { host: 'localhost:3000',
'user-agent': 'curl/7.54.0',
accept: '*/*',
'x-correlation-id': '1' }
s1: curl headers { host: 'localhost:3000',
'user-agent': 'curl/7.54.0',
accept: '*/*',
'x-correlation-id': '2' }
s1: response { 'x-correlation-id': '2',
'content-type': 'text/plain',
date: 'Tue, 30 Oct 2018 22:18:56 GMT',
connection: 'close',
'content-length': '14' }
Hello, World!
s1: response { 'x-correlation-id': '2',
'content-type': 'text/plain',
date: 'Tue, 30 Oct 2018 22:18:58 GMT',
connection: 'close',
'content-length': '14' }
Hello, World!
Hmm… The second response has the wrong header.
What’s wrong with this? We wrap the emit function, assign a uuid or propagate the header. When we create an outgoing connection we assign the uuid we created before to the new request. And there is the bug, if we create a request before the response from the previous one comes in we overwrite the value.
How can we solve this?
We need some mechanism that is aware of the execution context.
Part 4 - async hooks
In JavaScript whenever you invoke an asynchronous action you create a resource with an async id. Those invocations are tied together by a parent - child relationship via triggered id.
A simple example will show how this works:
const asyncHooks = require('async_hooks');
const fs = require('fs');
const util = require('util');
function debug(...args) {
fs.writeSync(process.stdout.fd, `${util.format(...args)}`);
}
asyncHooks.createHook({
init(asyncId, type, triggerAsyncId) {
debug(`Init ${type} resource: asyncId: ${asyncId} trigger: ${triggerAsyncId}`);
},
destroy(asyncId) {
const eid = asyncHooks.executionAsyncId();
debug(`Destroy resource: execution: ${eid} asyncId: ${asyncId}`);
}
}).enable();
debug(`in top level: asyncId: ${asyncHooks.executionAsyncId()} trigger: ${asyncHooks.triggerAsyncId()}`);
setTimeout(() => {
debug(`in timeout: asyncId: ${asyncHooks.executionAsyncId()} trigger: ${asyncHooks.triggerAsyncId()}`);
}, 1000);
This outputs:
in top level: asyncId: 1 trigger: 0
Init Timeout resource: asyncId: 5 trigger: 1
Init TIMERWRAP resource: asyncId: 6 trigger: 1
in timeout: asyncId: 5 trigger: 1
Destroy resource: execution: 0 asyncId: 5
Destroy resource: execution: 0 asyncId: 6
We see that we can track each resource creation and then at the moment of invocation check the id using executionAsyncId. Using these methods we can create an execution context and store arbitrary information there. Here is a full implementation (the code is based on guyguyon but modified and simplified), let’s go through this:
const asyncHooks = require('async_hooks');
function getNamespace() {
const context = new Map();
const run = (fn) => {
const eid = asyncHooks.executionAsyncId();
context.set(eid, new Map());
fn();
}
const set = (key, val) => {
const eid = asyncHooks.executionAsyncId();
context.get(eid).set(key, val);
}
const get = (key) => {
const eid = asyncHooks.executionAsyncId();
return context.get(eid).get(key);
}
return {
run,
set,
get,
context
}
}
function createHooks(namespace) {
function init(asyncId, type, triggerId, resource) {
if (namespace.context.has(triggerId)) {
namespace.context.set(asyncId, namespace.context.get(triggerId));
}
}
function destroy(asyncId) {
namespace.context.delete(asyncId);
}
const hook = asyncHooks.createHook({
init,
destroy
});
hook.enable();
}
const namespace = getNamespace();
createHooks(namespace);
module.exports = {
namespace
}
We start with a getNamespace function. It creates a new context which is something we will put data associated with an execution context in. Then we have three functions:
run- gets the async id, and creates a newMapto store informationset- sets a key/value in a contextget- gets a value from a context given a key
Then we create an async hook, in init function we copy the parent’s value from the context to a child so that it can be accessed when it’s needed (further down the async stack). In destroy function we simply delete the value from the context.
Now everything is ready to be connected together.
Part 5 - tying everything together
Ok, now we can get back to the tracing code.
All we need to do is move the uuid to wrapped function code, set it in the context and get the uuid from the context when wrapping http.request.
Here is the full code:
const http = require('http');
const {uuidv4} = require('./uuid');
const {wrap} = require('./shimmer');
const {namespace} = require('./namespace');
const PROPAGATE_HEADER_NAME = 'x-correlation-id';
wrap(http.Server.prototype, 'emit', function (original) {
return function (event, incomingMessage, serverResponse) {
let returned;
if (event === 'request') {
let uuid;
if (incomingMessage.headers[PROPAGATE_HEADER_NAME]) {
uuid = incomingMessage.headers[PROPAGATE_HEADER_NAME];
} else {
uuid = uuidv4();
}
serverResponse.setHeader(PROPAGATE_HEADER_NAME, uuid);
namespace.run(() => { // here we set the uuid in a namespace
namespace.set('tid', uuid);
returned = original.apply(this, arguments);
});
} else {
returned = original.apply(this, arguments);
}
return returned;
};
});
wrap(http, 'request', function (original) {
return function (options) {
options.headers = options.headers || {};
options.headers[PROPAGATE_HEADER_NAME] = namespace.get('tid'); // here we read from it
return original.apply(this, arguments);
};
});
Running this in our test bench yields:
s1: curl headers { host: 'localhost:3000',
'user-agent': 'curl/7.54.0',
accept: '*/*',
'x-correlation-id': '1' }
s1: curl headers { host: 'localhost:3000',
'user-agent': 'curl/7.54.0',
accept: '*/*',
'x-correlation-id': '2' }
s1: response { 'x-correlation-id': '2',
'content-type': 'text/plain',
date: 'Tue, 30 Oct 2018 22:25:58 GMT',
connection: 'close',
'content-length': '14' }
Hello, World!
s1: response { 'x-correlation-id': *'1'*,
'content-type': 'text/plain',
date: 'Tue, 30 Oct 2018 22:26:00 GMT',
connection: 'close',
'content-length': '14' }
Hello, World!
Which is exactly what we wanted.
Summary
We have successfully created a POC distributed tracing library. Of course there are more aspects to distributed tracing like: sampling, spans, collecting data, visualization, but this is still very impressive that we were able to do this in approximately 100 lines of code.
You can find complete source code on my github.

Krzysztof Słonka
Software engineer at Kong. Pragmatic programmer. Nowadays I mostly write "if err != nil"